The world plunged into panic after the initial outbreak of the “Swine Flu”, now called the A H1N1 virus, in Mexico. According to http://optinghealth.com report the Health Minister, Jose Angel Cordova, The first official case was a small five year old boy, and the child recovered. Continual updates have poured from the CDC, Center for Disease …
One out of five people experience the perception of sound when there is no actual external noise present. The condition is commonly referred to as ringing in the ears, medically known as tinnitus. The perception of sounds come in many forms such as buzzing, whistling, clicking, hissing, and in some cases hearing music. Tinnitus can be …
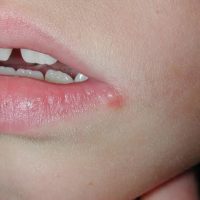
HSV or herpes virus can be gotten through sexual intercourse. You may also have it through other forms of sex like oral sex. You can get it via mouth or genitals. Either way, it is a big problem. It is also shameful on your part. It only means you didn’t have protected sex. Hence, the virus …
It’s not easy to lose weight especially if you’ve gotten used to eating unhealthy foods with no regular exercise. Aside from your diet, workout, lifestyle and attitude, there are things that are hard to control and make you struggle to lose weight. These include your rate of metabolism, some hormonal issues and age. The French people …
Nutritional facts about the steel cut oats The steel cut oats with the nutrients is made up of groats oats through the steel mill by chopping into pieces and the oats are variety of nutritional taste when comparing to the normal oats taste. The steel cut oats is acts as the cereals because it can be …